Analyzing Chess Input Modalities
April 16, 2026
In a previous post I benchmarked the current crop of frontier LLMs on chess ability. I found that Gemini 3.1 Pro and GPT 5.4 played at nearly an expert level. But as I read more about previous attempts to benchmark chess, I stumbled onto debates about how the input modality was impacting performance. I also noticed this anecdotally. I have a pet project trying to integrate a robotic arm with a vision-action model to get it to play a chess move end to end.

I've noticed that despite the fact that large foundation models have sophisticated chess understanding and strong vision capabilities, they still struggle to spatially reason about chess boards. To understand this better I built a series of diagnostic tests to have models solve chess puzzles using everything from move notation inputs to pictures of the board on my desk.
LLMs Struggle with 3D Vision Tasks
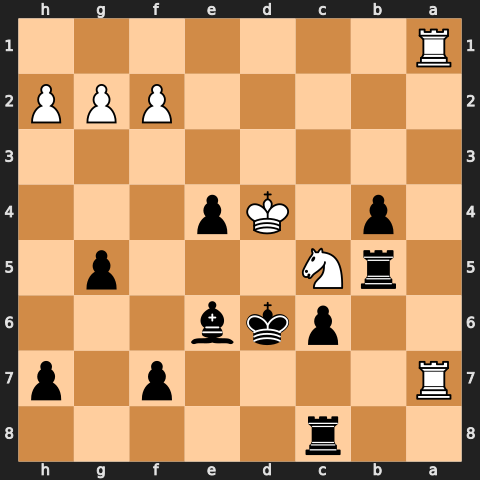
I picked 30 puzzles that varied from crowded middlegames down to simple endgames. They are all one-move puzzles that someone around 1000 Elo should be able to solve. I then rendered each puzzle in five different input modalities: UCI move history, PGN notation, a FEN string, a 2D PNG of the board, and a pair of photos of a real chess board on my desk captured from two angles. Below is an example of all five inputs for a middlegame puzzle.
e2e4 c7c5 g1f3 b8c6 d2d4 c5d4 f3d4 d8b6 d4b3 g8f6 c1e3 b6b4 b1d2 f6e4 c2c3 b4a4 d1g4 e4c3 f1c4 d7d5 g4h4 c3b5 b3c5 a4b4 a2a3 b4b2 a1b1 b2a3 c4b5 e7e6 c5b3 a3b4 b5c6 b7c6 h4b4 f8b4 e3c5 a7a5 c5b4 a5b4 b3c5 a8b8 d2b3 e8e7 e1d2 e7d6 b1a1 e6e5 a1a7 c8e6 h1a1 e5e4 d2e3 g7g5 e3d4 h8c8 b3d2 b8b5 d2e4 d5e4
1. e4 c5 2. Nf3 Nc6 3. d4 cxd4 4. Nxd4 Qb6 5. Nb3 Nf6 6. Be3 Qb4+ 7. N1d2 Nxe4 8. c3 Qa4 9. Qg4 Nxc3 10. Bc4 d5 11. Qh4 Nb5 12. Nc5 Qb4 13. a3 Qxb2 14. Rb1 Qxa3 15. Bxb5 e6 16. Ncb3 Qb4 17. Bxc6+ bxc6 18. Qxb4 Bxb4 19. Bc5 a5 20. Bxb4 axb4 21. Nc5 Rb8 22. Ndb3 Ke7 23. Kd2 Kd6 24. Ra1 e5 25. Ra7 Be6 26. Rha1 e4 27. Ke3 g5 28. Kd4 Rhc8 29. Nd2 Rb5 30. Ndxe4+ dxe4
2r5/R4p1p/2pkb3/1rN3p1/1p1Kp3/8/5PPP/R7 w - - 0 31


Each (model, modality) pair was graded on 30 single-shot attempts with no retries on illegal moves. The solve rates across the four test models are shown below.
| Model | UCI | PGN | FEN | PNG Image | Photos |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | 97% | 100% | 100% | 77% | 73% |
| GPT 5.4 | 93% | 100% | 100% | 93% | 40% |
| Opus 4.7 | 53% | 50% | 50% | 57% | 20% |
| Opus 4.6 | 33% | 33% | 40% | 20% | 17% |
| Qwen 3.5 27B | 13% | 7% | 23% | 37% | 17% |
30 one-move puzzles per cell, thinking effort set to “low” for every model.
The models previously found to excel at chess have nearly perfect understanding of notation based game input. Interestingly, GPT 5.4 does quite well on the 2D PNG task but poorly on 3D. Gemini is the only model with a credible attempt on the 3D photos. This matches my finding from earlier in the week that Gemini models are able to recreate the board from 3D images much better than any other model.
Qwen is the only model that seems to outperform with vision instead of text. This is quite surprising to me. I do not know the exact reason but will explore it a bit later on.
Can Gemini See the Board?
To separate vision from solving, I asked Gemini to transcribe each position to FEN and compared the transcription to the actual values.
| Metric | PNG Image | Photos |
|---|---|---|
| FEN read exactly right | 93% | 33% |
| Puzzle solved | 77% | 73% |
| Mean squares correct (of 64) | 63.9 | 61.0 |
30 puzzles per modality.
Interestingly, Gemini struggles with each task for different reasons. For PNG images, it understands the board perfectly but is unable to convert this understanding to a puzzle solve with only limited thinking. This is obviously somewhat strange given that it can solve the puzzle with the FEN, but presumably the intermediate decode step has some cost.
For the 3D photos, Gemini is often off by one or two piece locations. However, if these pieces are immaterial to the solve it can still piece together the correct puzzle solution.
Looking Inside Qwen’s Activations
I generated 2,000 synthetic positions for four of the five input modalities (2,000 photos was too much work), ran them through Qwen 3.5 27B, and pulled the residual-stream activations at every layer. I measured similarity with Centered Kernel Alignment, a standard way to check whether two sets of activations encode the same information.
There’s one issue with raw CKA values though. Two activation streams can score high just because they share the same prompt structure and length. To work around this I built a stricter null: instead of comparing raw values, the chart shows how much each pair beats a position-pairing shuffle within tight piece-count and ply buckets. The null absorbs everything that’s not actually about the chess content (the system prompt, the template structure, the prompt length, the position complexity), so what’s left above zero is the content-driven alignment in the residual stream.
Two clusters jump out in the late layers. FEN, PNG, and UCI all converge into the same shared board representation: FEN↔PNG peaks at +0.68 above the null, with UCI↔FEN and UCI↔PNG close behind around +0.54. UCI↔PGN, on the other hand, only gets to about +0.29.
I’m not really sure why this happens. However, we see empirically that Qwen is the worst at solving PGN puzzles. So perhaps this is showing that there is some underlying board representation understanding that the PGN puzzles do not activate.